25. microgpt.py を Mojo で書き直す
25.1. この章で学ぶこと
microgpt.pyのB1〜B7 ブロックが Mojo でどう書かれているか、ソースコードを読みながら理解するMojo の所有権・テープ(計算グラフ)・構造体を、動くコードの上で確認する
Python の
Valueクラスを Mojo のTape(インデックスベース)に置き換えた設計上の理由を知るmain.mojoで B1〜B7 を組み合わせた学習・推論の全体像を把握する
25.2. 実行例
src/part3/microgpt_mojo/ で次のように実行します。
cd src/part3/microgpt_mojo
mojo run main.mojo
出力(学習ステップは途中を省略):
num docs: 32033
vocab size: 27
num params: 4192
step 1 / 1000 | loss 3.2589016467713185
step 2 / 1000 | loss 3.4757539661271393
step 3 / 1000 | loss 3.2850563256139123
step 4 / 1000 | loss 3.2385487413715050
step 5 / 1000 | loss 3.4347922579358574
...
step 996 / 1000 | loss 1.9243386681471330
step 997 / 1000 | loss 2.2576022798634730
step 998 / 1000 | loss 1.6500781354343423
step 999 / 1000 | loss 1.9544453781129398
step 1000 / 1000 | loss 2.5348443763481185
--- inference ---
sample 1 : ala
sample 2 : nayna
sample 3 : anare
sample 4 : alania
sample 5 : odelen
sample 6 : sona
sample 7 : adila
sample 8 : kais
sample 9 : tayna
sample 10 : adelel
sample 11 : atena
sample 12 : koncy
sample 13 : maneza
sample 14 : aleran
sample 15 : amelin
sample 16 : tirha
sample 17 : saria
sample 18 : tanin
sample 19 : jaian
sample 20 : astyan
loss が 3.2 前後から 1.6〜2.5 程度まで下がり、推論では名前らしい文字列(“ala”, “sona”, “adelel” など)が生成されていることが確認できます。
25.3. 全体構造
25.3.1. B1〜B7 の依存関係
各ブロックは以下のように依存しています。矢印は「使う→使われる」の方向です。

B3(Tape)がすべての土台です。演算のたびにノードをテープに追記し、逆伝播で勾配を計算します。B4〜B7 はテープ上のノード ID(Int)を受け渡しながら動きます。
25.3.2. ファイル構成
ファイル |
対応する Python の概念 |
主な内容 |
|---|---|---|
|
|
テキストから文書リストを作る |
|
|
文字→IDの変換 |
|
|
自動微分テープ |
|
|
モデル重みの初期化・管理 |
|
|
テープ上のテンソル演算 |
|
|
GPT 1ステップの順伝播 |
|
学習ループの核 |
損失計算・Adam 更新 |
|
推論ループの核 |
温度付きサンプリング |
|
スクリプト本体 |
全体を組み合わせた実行ファイル |
25.3.3. データとコードの流れ

25.4. B1 — データセット(b01_dataset.mojo)
25.4.1. ソースコード
# B1: Build non-empty stripped lines from multi-line text (like input.txt).
def load_docs_from_text(text: String) -> List[String]:
var docs = List[String]()
var lines = text.splitlines()
for i in range(len(lines)):
var line = String(String(lines[i]).strip())
if len(line) > 0:
docs.append(line)
return docs^
def load_sample_names() -> List[String]:
# Tiny fixed corpus for tests (ASCII names, one per line).
return load_docs_from_text(String("ada\nbob\n\nada\n"))
25.4.2. 解説
load_docs_from_text は input.txt の中身(文字列)を受け取り、空行を除いた行のリストを返します。
var lines = text.splitlines() # 改行で分割
var line = String(String(lines[i]).strip()) # 前後の空白を除去
if len(line) > 0: # 空行をスキップ
docs.append(line)
String(String(lines[i]).strip()) と 2 重に String() が現れているのは、型変換が 2 段階必要なためです。
式 |
型 |
説明 |
|---|---|---|
|
|
|
|
|
所有権のあるコピーに変換 |
|
|
前後の空白を除いた部分への参照(所有権なし) |
|
|
所有権のあるコピーに変換 ← これを |
strip() の戻り値が StringSlice(参照)であることが核心です。List[String] に append するには所有権のある String が必要なので、外側の String(...) でもう一度コピーを作っています。
関数の末尾で return docs^ と書いているのは、docs をコピーせず転送(move)して返すためです。^ は「所有権をここで手放す」という演算子で、不要なコピーを避けます。
load_sample_names はテスト用の小さなデータセット(3件の名前)を固定文字列から作る便利関数です。
25.5. B2 — トークナイザー(b02_tokenizer.mojo)
25.5.1. ソースコード
# B2: Char-level tokenizer (sorted unique chars + BOS), matching microgpt.py.
from std.builtin.sort import sort
struct Tokenizer:
var uchars: List[String]
var bos: Int
def __init__(out self, uchars: List[String], bos: Int):
self.uchars = uchars.copy()
self.bos = bos
def vocab_size(self) -> Int:
return len(self.uchars) + 1
def _char_at(doc: String, j: Int) -> String:
return chr(Int(doc.as_bytes()[j]))
def _find_char(uchars: List[String], ch: String) -> Int:
for i in range(len(uchars)):
if uchars[i] == ch:
return i
return -1
def build_tokenizer(docs: List[String]) -> Tokenizer:
var chars = List[String]()
for di in range(len(docs)):
var d = docs[di]
for j in range(len(d)):
var ch = _char_at(d, j)
if _find_char(chars, ch) < 0:
chars.append(ch)
sort(chars)
var bos = len(chars)
return Tokenizer(chars^, bos)
def encode_doc(tok: Tokenizer, doc: String) -> List[Int]:
var out = List[Int]()
out.append(tok.bos)
for j in range(len(doc)):
var ch = _char_at(doc, j)
var ix = _find_char(tok.uchars, ch)
out.append(ix)
out.append(tok.bos)
return out^
25.5.2. 解説
25.5.2.1. Tokenizer 構造体
struct Tokenizer:
var uchars: List[String] # 語彙: ソート済みユニーク文字の一覧
var bos: Int # BOS トークンの ID(= len(uchars))
uchars は ['a', 'b', ..., 'z'] のような文字リストで、インデックスがそのままトークン ID になります。BOS(Beginning of Sequence) は文の先頭・末尾を示す特殊トークンで、文字数より 1 大きい ID を持ちます。
25.5.2.2. トークン化の例
文書 "ada" をトークン化すると次のようになります。

encode_doc は [BOS, id('a'), id('d'), id('a'), BOS] というリストを作ります。学習時は位置 t のトークンから位置 t+1 のトークンを予測するタスクになります。
25.5.2.3. 文字の取り出し
def _char_at(doc: String, j: Int) -> String:
return chr(Int(doc.as_bytes()[j]))
Python では doc[j:j+1] でスライスできましたが、Mojo 0.26 では String のスライスが直接 String を返さないため、as_bytes() でバイト列を取り出し chr() で文字に変換しています(ASCII 文字専用の教材向けの実装です)。
25.5.2.4. バブルソート
Python の sorted(set(...)) に相当する処理は from std.builtin.sort import sort でインポートした sort() で行います。sort(chars) と呼ぶだけで List[String] をインプレースにソートできます。
25.6. B3 — 自動微分テープ(b03_value.mojo)
25.6.1. ソースコード
# B3: Scalar autograd tape (microgpt.py Value), topology-order backward.
# Stored as structure-of-arrays so nodes stay in List[...] without custom copy/move.
from std.math import exp, log
comptime NodeId = Int
struct Tape:
var data: List[Float64]
var grad: List[Float64]
var children: List[List[Int]]
var local_grads: List[List[Float64]]
def __init__(out self):
self.data = List[Float64]()
self.grad = List[Float64]()
self.children = List[List[Int]]()
self.local_grads = List[List[Float64]]()
def _push_node(
mut self, value: Float64, ch: List[Int], lg: List[Float64]
) -> NodeId:
self.data.append(value)
self.grad.append(0.0)
self.children.append(ch.copy())
self.local_grads.append(lg.copy())
return len(self.data) - 1
def node_data(self, i: NodeId) -> Float64:
return self.data[i]
def grad_at(self, i: NodeId) -> Float64:
return self.grad[i]
def set_data(mut self, i: NodeId, v: Float64):
self.data[i] = v
def set_grad(mut self, i: NodeId, g: Float64):
self.grad[i] = g
def add_grad(mut self, i: NodeId, d: Float64):
self.grad[i] += d
def clear_grads(mut self):
for i in range(len(self.grad)):
self.grad[i] = 0.0
def leaf(mut self, value: Float64) -> NodeId:
var ch = List[Int]()
var lg = List[Float64]()
return self._push_node(value, ch^, lg^)
def add(mut self, a: NodeId, b: NodeId) -> NodeId:
var ch = List[Int]()
ch.append(a)
ch.append(b)
var lg = List[Float64]()
lg.append(1.0)
lg.append(1.0)
var s = self.data[a] + self.data[b]
return self._push_node(s, ch^, lg^)
def mul(mut self, a: NodeId, b: NodeId) -> NodeId:
var ch = List[Int]()
ch.append(a)
ch.append(b)
var lg = List[Float64]()
lg.append(self.data[b])
lg.append(self.data[a])
var p = self.data[a] * self.data[b]
return self._push_node(p, ch^, lg^)
def neg(mut self, a: NodeId) -> NodeId:
var ch = List[Int]()
ch.append(a)
var lg = List[Float64]()
lg.append(-1.0)
return self._push_node(-self.data[a], ch^, lg^)
def sub(mut self, a: NodeId, b: NodeId) -> NodeId:
return self.add(a, self.neg(b))
def pow_const(mut self, a: NodeId, expv: Float64) -> NodeId:
var ad = self.data[a]
var y = ad**expv
var lg = expv * ad ** (expv - 1.0)
var ch = List[Int]()
ch.append(a)
var lgs = List[Float64]()
lgs.append(lg)
return self._push_node(y, ch^, lgs^)
def div(mut self, a: NodeId, b: NodeId) -> NodeId:
var invb = self.pow_const(b, -1.0)
return self.mul(a, invb)
def log_(mut self, a: NodeId) -> NodeId:
var ad = self.data[a]
var ch = List[Int]()
ch.append(a)
var lg = List[Float64]()
lg.append(1.0 / ad)
return self._push_node(log(ad), ch^, lg^)
def exp_(mut self, a: NodeId) -> NodeId:
var ad = self.data[a]
var y = exp(ad)
var ch = List[Int]()
ch.append(a)
var lg = List[Float64]()
lg.append(y)
return self._push_node(y, ch^, lg^)
def relu(mut self, a: NodeId) -> NodeId:
var ad = self.data[a]
var y = ad if ad > 0.0 else 0.0
var g = 1.0 if ad > 0.0 else 0.0
var ch = List[Int]()
ch.append(a)
var lg = List[Float64]()
lg.append(g)
return self._push_node(y, ch^, lg^)
def sum_nodes(mut self, xs: List[Int]) -> NodeId:
if len(xs) == 0:
return self.leaf(0.0)
var s = xs[0]
for i in range(1, len(xs)):
s = self.add(s, xs[i])
return s
def scale(mut self, a: NodeId, s: Float64) -> NodeId:
return self.mul(a, self.leaf(s))
def _build_topo(mut tape: Tape, v: NodeId, mut topo: List[Int], mut visited: List[Bool]):
if visited[v]:
return
visited[v] = True
var ch = tape.children[v].copy()
for i in range(len(ch)):
_build_topo(tape, ch[i], topo, visited)
topo.append(v)
def backward(mut tape: Tape, root: NodeId):
tape.clear_grads()
var visited = List[Bool]()
for _ in range(len(tape.data)):
visited.append(False)
var topo = List[Int]()
_build_topo(tape, root, topo, visited)
tape.set_grad(root, 1.0)
var ti = len(topo)
while ti > 0:
ti -= 1
var v = topo[ti]
var gv = tape.grad[v]
var ch = tape.children[v].copy()
var lgs = tape.local_grads[v].copy()
for k in range(len(ch)):
var c = ch[k]
var lg = lgs[k]
tape.add_grad(c, lg * gv)
25.6.2. Tape の仕組み
これが最も重要なモジュールです。GPT の学習には「どのパラメータをどの方向に動かすか」を知るための勾配計算が必要です。Tape はその計算グラフを管理します。
注釈
「テープ」という名前の由来
「テープ」は自動微分の歴史的な用語です。1964 年に R. E. Wengert が提案した「演算を順番に書き留めたリスト(Wengert list)」が起源で、テープレコーダーが音声を順に記録するように、順伝播中のすべての演算を記録していくことからこう呼ばれます。この方式を「テープベース自動微分(tape-based AD)」といいます。
TensorFlow には同じ概念の tf.GradientTape という API があり、PyTorch 内部でも “gradient tape” という用語が使われています。
Python 版の Value が「微分可能な値 1 個」を表す名前なのに対し、Mojo 版の Tape は「演算の記録装置全体」を表す名前です。Mojo の所有権制約で自己参照構造体が作れないため、全ノードを 1 つの構造体に集約する設計になり、その結果としてテープという概念と自然に一致しました。
演算(加算・乗算など)を呼ぶたびに、Tape は新しいノードを 4 つの配列に追記します。
配列 |
内容 |
|---|---|
|
ノード i の計算値 |
|
ノード i の勾配(逆伝播後) |
|
子ノードの ID 列 |
|
各子ノードへの局所勾配 |
25.6.2.1. 具体例: c = a + b
var a = t.leaf(2.0) # ノード 0: data=2.0
var b = t.leaf(3.0) # ノード 1: data=3.0
var c = t.add(a, b) # ノード 2: data=5.0, children=[0,1], local_grads=[1.0,1.0]
テープの内部状態はこうなります。
index |
data |
grad |
children |
local_grads |
|---|---|---|---|---|
0 |
2.0 |
0.0 |
|
|
1 |
3.0 |
0.0 |
|
|
2 |
5.0 |
0.0 |
|
|
加算の局所勾配はどちらも 1.0 です(∂(a+b)/∂a = 1、∂(a+b)/∂b = 1)。
乗算 c = a * b の場合は local_grads = [b.data, a.data](∂(a*b)/∂a = b、∂(a*b)/∂b = a)になります。
25.6.2.2. 逆伝播アルゴリズム
backward(tape, root) はルートノードから勾配を伝播します。

clear_grads()で全勾配をゼロにリセットトポロジカルソートで「子より親が後」の順に並べる
ルートの勾配を 1.0 にセット(
∂loss/∂loss = 1)逆順に辿りながら
child.grad += local_grad × node.gradを累積
連鎖律(chain rule)の実装そのものです。
25.6.2.3. sum_nodes で sum() を使わない理由
sum_nodes は xs: List[Int] を受け取りますが、この Int は数値ではなくノード IDです。
注釈
xs の中身はたとえば [42, 57, 63] のような整数ですが、これは「テープの 42 番目・57 番目・63 番目のノード」を指すインデックスです。
sum(xs) を使うと 42 + 57 + 63 = 162 というインデックスの和が計算されてしまい、まったく意味が違います。
self.add(a, b) を繰り返す理由は、単に数値を足すのではなく、テープに加算ノードを追記するためです。
xs = [42, 57, 63] (ノード ID)
step1: s = self.add(42, 57) → テープにノード 100 を追記(children=[42,57])
step2: s = self.add(100, 63) → テープにノード 101 を追記(children=[100,63])
return 101 (総和を表すノードの ID)
このノードの連鎖があることで、backward() 時に勾配が各子ノードへ正しく伝播できます。sum() で単純に足すと計算グラフが作られず、逆伝播できません。
25.7. B4 — ハイパーパラメータと重み(b04_state_dict.mojo)
25.7.1. ソースコード
# B4: Model hyperparameters, weight matrices of Tape nodes, flat param list.
from std.random import randn_float64
from b03_value import NodeId, Tape
struct HyperParams:
var n_layer: Int
var n_embd: Int
var block_size: Int
var n_head: Int
def __init__(out self, n_layer: Int, n_embd: Int, block_size: Int, n_head: Int):
self.n_layer = n_layer
self.n_embd = n_embd
self.block_size = block_size
self.n_head = n_head
def head_dim(self) -> Int:
return self.n_embd // self.n_head
struct StateDict:
var wte: List[List[Int]]
var wpe: List[List[Int]]
var lm_head: List[List[Int]]
var attn_wq: List[List[List[Int]]]
var attn_wk: List[List[List[Int]]]
var attn_wv: List[List[List[Int]]]
var attn_wo: List[List[List[Int]]]
var mlp_fc1: List[List[List[Int]]]
var mlp_fc2: List[List[List[Int]]]
def __init__(
out self,
wte: List[List[Int]],
wpe: List[List[Int]],
lm_head: List[List[Int]],
attn_wq: List[List[List[Int]]],
attn_wk: List[List[List[Int]]],
attn_wv: List[List[List[Int]]],
attn_wo: List[List[List[Int]]],
mlp_fc1: List[List[List[Int]]],
mlp_fc2: List[List[List[Int]]],
):
self.wte = wte.copy()
self.wpe = wpe.copy()
self.lm_head = lm_head.copy()
self.attn_wq = attn_wq.copy()
self.attn_wk = attn_wk.copy()
self.attn_wv = attn_wv.copy()
self.attn_wo = attn_wo.copy()
self.mlp_fc1 = mlp_fc1.copy()
self.mlp_fc2 = mlp_fc2.copy()
def matrix_rand(mut t: Tape, nout: Int, nin: Int, std: Float64) -> List[List[Int]]:
var m = List[List[Int]]()
for _ in range(nout):
var row = List[Int]()
for _ in range(nin):
row.append(t.leaf(randn_float64(0.0, std)))
m.append(row^)
return m^
def init_state_dict(mut t: Tape, vocab_size: Int, hp: HyperParams, std: Float64) -> StateDict:
var wte = matrix_rand(t, vocab_size, hp.n_embd, std)
var wpe = matrix_rand(t, hp.block_size, hp.n_embd, std)
var lm_head = matrix_rand(t, vocab_size, hp.n_embd, std)
var attn_wq = List[List[List[Int]]]()
var attn_wk = List[List[List[Int]]]()
var attn_wv = List[List[List[Int]]]()
var attn_wo = List[List[List[Int]]]()
var mlp_fc1 = List[List[List[Int]]]()
var mlp_fc2 = List[List[List[Int]]]()
for _ in range(hp.n_layer):
attn_wq.append(matrix_rand(t, hp.n_embd, hp.n_embd, std))
attn_wk.append(matrix_rand(t, hp.n_embd, hp.n_embd, std))
attn_wv.append(matrix_rand(t, hp.n_embd, hp.n_embd, std))
attn_wo.append(matrix_rand(t, hp.n_embd, hp.n_embd, std))
mlp_fc1.append(matrix_rand(t, 4 * hp.n_embd, hp.n_embd, std))
mlp_fc2.append(matrix_rand(t, hp.n_embd, 4 * hp.n_embd, std))
return StateDict(
wte^,
wpe^,
lm_head^,
attn_wq^,
attn_wk^,
attn_wv^,
attn_wo^,
mlp_fc1^,
mlp_fc2^,
)
def _append_matrix_flat(mut ps: List[NodeId], mat: List[List[Int]]):
for i in range(len(mat)):
var ncol = len(mat[i])
for j in range(ncol):
ps.append(mat[i][j])
def flatten_params(sd: StateDict) -> List[NodeId]:
var ps = List[NodeId]()
_append_matrix_flat(ps, sd.wte)
_append_matrix_flat(ps, sd.wpe)
_append_matrix_flat(ps, sd.lm_head)
for li in range(len(sd.attn_wq)):
_append_matrix_flat(ps, sd.attn_wq[li])
_append_matrix_flat(ps, sd.attn_wk[li])
_append_matrix_flat(ps, sd.attn_wv[li])
_append_matrix_flat(ps, sd.attn_wo[li])
_append_matrix_flat(ps, sd.mlp_fc1[li])
_append_matrix_flat(ps, sd.mlp_fc2[li])
return ps^
25.7.2. 解説
25.7.2.1. HyperParams
var hp = HyperParams(1, 16, 16, 4)
# n_layer=1, n_embd=16, block_size=16, n_head=4
GPT の形状を決めるパラメータです。head_dim() メソッドは n_embd ÷ n_head(各アテンションヘッドの次元数)を返します。
25.7.2.2. StateDict — 重みの束
重み行列の各要素はテープ上のノード ID(Int)として保存されています。つまり wte[0][3] は「単語 0 の埋め込みベクトルの 3 番目の要素に対応するノードの ID」です。

25.7.2.3. matrix_rand — 重みの初期化
row.append(t.leaf(randn_float64(0.0, std)))
from std.random import randn_float64 でインポートした randn_float64(mean, std) を使い、Python 版の random.gauss(0, std) と同等の正規分布乱数で重みを初期化しています。
25.7.2.4. flatten_params
Adam 更新ループで全パラメータを一括処理するため、行列の入れ子をフラットな List[NodeId] に展開します。
25.8. B5a — 演算ユーティリティ(b05_ops.mojo)
25.8.1. ソースコード
# B5a: linear, rmsnorm, softmax on Tape nodes (microgpt.py helpers).
from std.math import sqrt
from b03_value import Tape, NodeId
def linear(mut t: Tape, x: List[Int], w: List[List[Int]]) -> List[Int]:
var out = List[Int]()
for r in range(len(w)):
var acc = t.mul(x[0], w[r][0])
for c in range(1, len(x)):
acc = t.add(acc, t.mul(x[c], w[r][c]))
out.append(acc)
return out^
def dot(mut t: Tape, a: List[Int], b: List[Int]) -> NodeId:
var acc = t.mul(a[0], b[0])
for i in range(1, len(a)):
acc = t.add(acc, t.mul(a[i], b[i]))
return acc
def rmsnorm(mut t: Tape, x: List[Int]) -> List[Int]:
var sq = List[Int]()
for i in range(len(x)):
sq.append(t.mul(x[i], x[i]))
var ms = t.scale(t.sum_nodes(sq), 1.0 / Float64(len(x)))
var inv_rms = t.pow_const(t.add(ms, t.leaf(1e-5)), -0.5)
var out = List[Int]()
for i in range(len(x)):
out.append(t.mul(x[i], inv_rms))
return out^
def softmax(mut t: Tape, logits: List[Int]) -> List[Int]:
var m = t.node_data(logits[0])
for i in range(1, len(logits)):
var v = t.node_data(logits[i])
m = m if m > v else v
var exps = List[Int]()
for i in range(len(logits)):
exps.append(t.exp_(t.sub(logits[i], t.leaf(m))))
var s = t.sum_nodes(exps)
var out = List[Int]()
for i in range(len(exps)):
out.append(t.div(exps[i], s))
return out^
def scaled_attention_logits(
mut t: Tape, q_h: List[Int], k_rows: List[List[Int]], head_dim: Int
) -> List[Int]:
var logits = List[Int]()
var scale = 1.0 / sqrt(Float64(head_dim))
for tk in range(len(k_rows)):
logits.append(t.scale(dot(t, q_h, k_rows[tk]), scale))
return logits^
25.8.2. 解説
すべての関数は Tape 上に演算ノードを追加しながら、ノード ID のリストを入出力します。
25.8.2.1. linear(線形変換)
![\text{out}[r] = \sum_{c=0}^{C-1} W[r][c] \cdot x[c]](../_images/math/7b99a0dea03740f13c66cf09716e017825c58354.png)
out[r] = x[0]*w[r][0] + x[1]*w[r][1] + ... + x[C-1]*w[r][C-1]
行列 w(形状 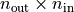 )の r 行目と入力ベクトル
)の r 行目と入力ベクトル x(長さ 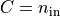 )の内積です。行列とベクトルの積
)の内積です。行列とベクトルの積 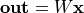 を1行ずつ計算しています。Python の
を1行ずつ計算しています。Python の sum(wi*xi ...) に相当します。
25.8.2.2. rmsnorm(RMS 正規化)
LayerNorm の簡略版です。各要素を「二乗平均の平方根」で割って正規化します。
![\text{rms} = \sqrt{\frac{1}{n}\sum_{i=0}^{n-1} x[i]^2 + \varepsilon}, \qquad \text{out}[i] = \frac{x[i]}{\text{rms}}](../_images/math/7a9d244ba1cb6078b9bc7d8d2ca3526386029539.png)
rms = sqrt( (x[0]² + x[1]² + ... + x[n-1]²) / n + ε )
out[i] = x[i] / rms
pow_const(node, -0.5) で 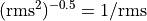 を計算し、これを全要素に掛けています。
を計算し、これを全要素に掛けています。
25.8.2.3. softmax
logits を確率分布に変換します。数値安定化のため最大値 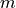 を引いてから exp を取ります(値が大きすぎて exp がオーバーフローするのを防ぐ)。
を引いてから exp を取ります(値が大きすぎて exp がオーバーフローするのを防ぐ)。
![p[i] = \frac{\exp(\text{logits}[i] - m)}{\sum_j \exp(\text{logits}[j] - m)}, \qquad m = \max_j \text{logits}[j]](../_images/math/417dbd77fb6ba9573b8b6ba205ec06d7250b9089.png)
m = max(logits[0], logits[1], ..., logits[V-1])
e[i] = exp(logits[i] - m)
p[i] = e[i] / (e[0] + e[1] + ... + e[V-1])
var m = t.node_data(logits[0]) # 現在の値(.data)を取り出し
for i in range(1, len(logits)):
var v = t.node_data(logits[i])
m = m if m > v else v # 最大値を求める
ここで t.node_data(...) を呼んでいるのは、最大値は定数扱いで微分不要なためです(ソフトマックスの安定化はグラフに乗せない)。
25.8.2.4. scaled_attention_logits
Query と Key の内積にスケール 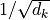 を掛けます。
を掛けます。
![\text{logits}[t] = \frac{\mathbf{q} \cdot \mathbf{k}_t}{\sqrt{d_k}}](../_images/math/994934deaa2ba2059aae20e26664fb1e025367a3.png)
logits[t] = (q[0]*k_t[0] + q[1]*k_t[1] + ... + q[d-1]*k_t[d-1]) / sqrt(d_k)
スケールしないと内積が 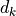 に比例して大きくなり、softmax 後の分布が一点に集中してしまいます。
に比例して大きくなり、softmax 後の分布が一点に集中してしまいます。
25.9. B5b — GPT 順伝播(b05_gpt.mojo)
25.9.1. ソースコード
# B5b: One-step GPT forward with KV cache (microgpt.py gpt).
from b03_value import Tape
from b04_state_dict import HyperParams, StateDict
from b05_ops import linear, rmsnorm, softmax, scaled_attention_logits
def row_embedding(mat: List[List[Int]], idx: Int) -> List[Int]:
var out = List[Int]()
var n = len(mat[idx])
for i in range(n):
out.append(mat[idx][i])
return out^
def slice_vec(xs: List[Int], start: Int, width: Int) -> List[Int]:
var out = List[Int]()
for j in range(width):
out.append(xs[start + j])
return out^
def head_slice_from_cache(cache: List[List[Int]], tix: Int, head_start: Int, head_dim: Int) -> List[Int]:
var out = List[Int]()
for j in range(head_dim):
out.append(cache[tix][head_start + j])
return out^
def attn_head(
mut t: Tape,
q_h: List[Int],
k_rows: List[List[Int]],
v_rows: List[List[Int]],
head_dim: Int,
) -> List[Int]:
var logits = scaled_attention_logits(t, q_h, k_rows, head_dim)
var w = softmax(t, logits^)
var head_out = List[Int]()
for j in range(head_dim):
var acc = t.mul(w[0], v_rows[0][j])
for tk in range(1, len(v_rows)):
acc = t.add(acc, t.mul(w[tk], v_rows[tk][j]))
head_out.append(acc)
return head_out^
def concat_heads(heads: List[List[Int]]) -> List[Int]:
var out = List[Int]()
for hi in range(len(heads)):
var nh = len(heads[hi])
for j in range(nh):
out.append(heads[hi][j])
return out^
def append_kv_row(mut cache: List[List[Int]], row: List[Int]):
cache.append(row.copy())
def gpt_forward(
mut t: Tape,
sd: StateDict,
hp: HyperParams,
token_id: Int,
pos_id: Int,
mut keys: List[List[List[Int]]],
mut vals: List[List[List[Int]]],
) -> List[Int]:
var hd = hp.head_dim()
var tok = row_embedding(sd.wte, token_id)
var pos = row_embedding(sd.wpe, pos_id)
var x = List[Int]()
for i in range(len(tok)):
x.append(t.add(tok[i], pos[i]))
x = rmsnorm(t, x^)
for li in range(hp.n_layer):
var x_res = List[Int]()
for j in range(len(x)):
x_res.append(x[j])
var x_ln = rmsnorm(t, x^)
var q = linear(t, x_ln, sd.attn_wq[li])
var k = linear(t, x_ln, sd.attn_wk[li])
var v = linear(t, x_ln, sd.attn_wv[li])
append_kv_row(keys[li], k^)
append_kv_row(vals[li], v^)
var heads = List[List[Int]]()
for h in range(hp.n_head):
var hs = h * hd
var q_h = slice_vec(q, hs, hd)
var k_h = List[List[Int]]()
var v_h = List[List[Int]]()
for tix in range(len(keys[li])):
k_h.append(head_slice_from_cache(keys[li], tix, hs, hd))
v_h.append(head_slice_from_cache(vals[li], tix, hs, hd))
var hpiece = attn_head(t, q_h, k_h, v_h, hd)
heads.append(hpiece^)
var merged = concat_heads(heads)
var x_attn = linear(t, merged, sd.attn_wo[li])
var x2 = List[Int]()
for j in range(len(x_attn)):
x2.append(t.add(x_attn[j], x_res[j]))
x = x2^
var xr2 = List[Int]()
for j in range(len(x)):
xr2.append(x[j])
var x_mlp_in = rmsnorm(t, x^)
var h1 = linear(t, x_mlp_in, sd.mlp_fc1[li])
var h2 = List[Int]()
for j in range(len(h1)):
h2.append(t.relu(h1[j]))
var x_mlp = linear(t, h2, sd.mlp_fc2[li])
var x3 = List[Int]()
for j in range(len(x_mlp)):
x3.append(t.add(x_mlp[j], xr2[j]))
x = x3^
return linear(t, x, sd.lm_head)
def gpt_forward_embed_only(mut t: Tape, sd: StateDict, token_id: Int, pos_id: Int) -> List[Int]:
var tok = row_embedding(sd.wte, token_id)
var pos = row_embedding(sd.wpe, pos_id)
var x = List[Int]()
for i in range(len(tok)):
x.append(t.add(tok[i], pos[i]))
x = rmsnorm(t, x^)
return linear(t, x, sd.lm_head)
25.9.2. 解説
gpt_forward が1ステップの GPT 計算です。1トークン分の入力を受け取り、次トークンの確率を示す logits ベクトルを返します。
25.9.2.1. 埋め込み層
var tok = row_embedding(sd.wte, token_id) # トークン埋め込み
var pos = row_embedding(sd.wpe, pos_id) # 位置埋め込み
var x = ... # tok + pos の要素和
x = rmsnorm(t, x^) # 初期正規化
row_embedding は行列の 1 行(= ノード ID の列)をコピーして返します。mat[idx] を直接返すのではなく mat[idx][i] と要素ごとに読むのは、行リストのムーブによる行列破壊を防ぐためです(後述)。
25.9.2.2. Transformer 層

25.9.2.3. KV キャッシュ
推論時も学習時も、過去のトークンで計算した Key/Value をリストに蓄積します。位置 t での Attention は位置 0〜t の K/V すべてに注目できます(因果的 Attention)。
append_kv_row(keys[li], k^) # この位置の Key をキャッシュに追加
append_kv_row(vals[li], v^) # この位置の Value をキャッシュに追加
for tix in range(len(keys[li])):
k_h.append(head_slice_from_cache(keys[li], tix, hs, hd))
...
head_slice_from_cache が cache[tix] を丸ごと渡さず cache[tix][j + off] と要素アクセスしているのは、行リストのムーブを避けるためです。
25.9.2.4. マルチヘッドアテンション
for h in range(hp.n_head):
var hs = h * hd # このヘッドの開始インデックス
var q_h = slice_vec(q, hs, hd) # Q をヘッドごとに切り出す
# K/V も同様に head_slice_from_cache で切り出す
var hpiece = attn_head(t, q_h, k_h, v_h, hd)
heads.append(hpiece^)
var merged = concat_heads(heads) # ヘッドを連結して n_embd 次元に戻す
n_head 個のヘッドを独立に計算して最後に連結します。
25.10. B6 — 学習ステップ(b06_train.mojo)
25.10.1. ソースコード
# B6: One document training step — forward, cross-entropy loss, backward, Adam.
from std.math import sqrt
from b03_value import Tape, backward
from b04_state_dict import HyperParams, StateDict
from b05_gpt import gpt_forward
from b05_ops import softmax
def min_int(a: Int, b: Int) -> Int:
return a if a < b else b
def init_kv_cache(n_layer: Int, mut keys: List[List[List[Int]]], mut vals: List[List[List[Int]]]):
for _ in range(n_layer):
keys.append(List[List[Int]]())
vals.append(List[List[Int]]())
def loss_on_document(
mut t: Tape,
sd: StateDict,
hp: HyperParams,
tokens: List[Int],
mut keys: List[List[List[Int]]],
mut vals: List[List[List[Int]]],
) -> Int:
var n = min_int(hp.block_size, len(tokens) - 1)
var losses = List[Int]()
for pos_id in range(n):
var tid = tokens[pos_id]
var target = tokens[pos_id + 1]
var logits = gpt_forward(t, sd, hp, tid, pos_id, keys, vals)
var probs = softmax(t, logits)
var nll = t.neg(t.log_(probs[target]))
losses.append(nll)
return t.scale(t.sum_nodes(losses), 1.0 / Float64(n))
def adam_update(
mut tape: Tape,
params: List[Int],
mut m: List[Float64],
mut v: List[Float64],
step_idx: Int,
total_steps: Int,
):
var lr = 0.01
var beta1 = 0.85
var beta2 = 0.99
var eps = 1e-8
var lr_t = lr * (1.0 - Float64(step_idx) / Float64(total_steps))
var tstep = step_idx + 1
var b1_corr = 1.0
var b2_corr = 1.0
for _ in range(tstep):
b1_corr *= beta1
b2_corr *= beta2
for i in range(len(params)):
var pid = params[i]
var g = tape.grad_at(pid)
m[i] = beta1 * m[i] + (1.0 - beta1) * g
v[i] = beta2 * v[i] + (1.0 - beta2) * g * g
var m_hat = m[i] / (1.0 - b1_corr)
var v_hat = v[i] / (1.0 - b2_corr)
var newv = tape.node_data(pid) - lr_t * m_hat / (sqrt(v_hat) + eps)
tape.set_data(pid, newv)
tape.set_grad(pid, 0.0)
25.10.2. 解説
25.10.2.1. loss_on_document — 1文書の損失
1文書分のトークン列に対して損失を計算します。
for pos_id in range(n):
var tid = tokens[pos_id] # 現在のトークン
var target = tokens[pos_id + 1] # 次のトークン(正解ラベル)
var logits = gpt_forward(...)
var probs = softmax(t, logits)
var nll = t.neg(t.log_(probs[target])) # 負の対数尤度
losses.append(nll)
return t.scale(t.sum_nodes(losses), 1.0 / Float64(n)) # 平均損失
正解トークン target の確率 probs[target] を取り出し、その対数の符号反転(NLL)を損失とします。予測が正確なほど確率は 1 に近づき、NLL は 0 に近づきます。
25.10.2.2. adam_update — Adam 最適化
var lr_t = lr * (1.0 - Float64(step_idx) / Float64(total_steps)) # 線形学習率減衰
m[i] = beta1 * m[i] + (1 - beta1) * g # 第1モーメント(勾配の移動平均)
v[i] = beta2 * v[i] + (1 - beta2) * g * g # 第2モーメント(勾配二乗の移動平均)
var m_hat = m[i] / (1 - b1_corr) # バイアス補正
var v_hat = v[i] / (1 - b2_corr)
var newv = tape.node_data(pid) - lr_t * m_hat / (sqrt(v_hat) + eps)
tape.set_data(pid, newv) # 重みの値を更新
tape.set_grad(pid, 0.0) # 勾配をリセット
Adam はモメンタム(第1モーメント)と RMSProp(第2モーメント)を組み合わせた最適化手法です。初期ステップのバイアスを 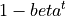 で補正しています。
で補正しています。
25.11. B7 — 推論ヘルパ(b07_infer.mojo)
25.11.1. ソースコード
# B7: Temperature-scaled softmax and greedy token pick (inference helpers).
from std.random import random_float64
from b03_value import Tape
from b05_ops import softmax
def logits_with_temperature(mut t: Tape, logits: List[Int], temperature: Float64) -> List[Int]:
var scaled = List[Int]()
var inv_t = 1.0 / temperature
for i in range(len(logits)):
scaled.append(t.scale(logits[i], inv_t))
return softmax(t, scaled)
def greedy_argmax(probs: List[Int], tape: Tape) -> Int:
var best = 0
var bestv = tape.node_data(probs[0])
for i in range(1, len(probs)):
var v = tape.node_data(probs[i])
if v > bestv:
bestv = v
best = i
return best
def sample_from_probs(probs: List[Int], tape: Tape) -> Int:
var r = random_float64()
var cumsum = 0.0
for i in range(len(probs)):
cumsum += tape.node_data(probs[i])
if r < cumsum:
return i
return len(probs) - 1
def should_stop(token_id: Int, bos_id: Int) -> Bool:
return token_id == bos_id
25.11.2. 解説
25.11.2.1. logits_with_temperature — 温度スケーリング
var inv_t = 1.0 / temperature
for i in range(len(logits)):
scaled.append(t.scale(logits[i], inv_t))
return softmax(t, scaled)
temperature が低い(例 0.5)ほど logits の差が拡大し、確率分布が尖って確定的な出力になります。temperature=1.0 では logits をそのまま使います。

25.11.2.2. sample_from_probs — 累積分布サンプリング
var r = random_float64() # [0, 1) の一様乱数
var cumsum = 0.0
for i in range(len(probs)):
cumsum += tape.node_data(probs[i])
if r < cumsum: # 累積確率が乱数を超えた時点で選択
return i
確率に比例した頻度でトークンを選びます。Python の random.choices(range(n), weights=probs) と同等です。

25.12. main.mojo — 全体を組み合わせる
25.12.1. ソースコード
# microgpt.py と同等の処理を Mojo で実装したメインファイル。
# B1〜B7 モジュールを組み合わせて学習と推論を行う。
from std.random import random_float64, seed
from b01_dataset import load_docs_from_text
from b02_tokenizer import build_tokenizer, encode_doc
from b03_value import Tape, backward
from b04_state_dict import HyperParams, init_state_dict, flatten_params
from b05_gpt import gpt_forward
from b06_train import init_kv_cache, loss_on_document, adam_update
from b07_infer import logits_with_temperature, sample_from_probs, should_stop
def main() raises:
seed(42) # 再現性のため乱数シードを固定(Python の random.seed(42) 相当)
# -------------------------------------------------------------------------
# データセット
# -------------------------------------------------------------------------
var f = open("input.txt", "r")
var text = f.read()
f.close()
var docs = load_docs_from_text(text)
# Fisher-Yates シャッフル
for i in range(len(docs) - 1, 0, -1):
var j = Int(random_float64() * Float64(i + 1))
var tmp = docs[i]
docs[i] = docs[j]
docs[j] = tmp
print("num docs:", len(docs))
# -------------------------------------------------------------------------
# トークナイザー
# -------------------------------------------------------------------------
var tok = build_tokenizer(docs)
print("vocab size:", tok.vocab_size())
# -------------------------------------------------------------------------
# ハイパーパラメータ
# -------------------------------------------------------------------------
# n_layer=1, n_embd=16, block_size=16, n_head=4
var hp = HyperParams(1, 16, 16, 4)
# -------------------------------------------------------------------------
# テープとパラメータの初期化
# -------------------------------------------------------------------------
var t = Tape()
var sd = init_state_dict(t, tok.vocab_size(), hp, 0.08)
var params = flatten_params(sd)
print("num params:", len(params))
# -------------------------------------------------------------------------
# Adam バッファ
# -------------------------------------------------------------------------
var m_buf = List[Float64]()
var v_buf = List[Float64]()
for _ in range(len(params)):
m_buf.append(0.0)
v_buf.append(0.0)
# -------------------------------------------------------------------------
# 学習ループ
# -------------------------------------------------------------------------
var num_steps = 1000
for step in range(num_steps):
var doc = docs[step % len(docs)]
var keys = List[List[List[Int]]]()
var vals = List[List[List[Int]]]()
init_kv_cache(hp.n_layer, keys, vals)
var tokens = encode_doc(tok, doc)
var loss_node = loss_on_document(t, sd, hp, tokens, keys, vals)
backward(t, loss_node)
adam_update(t, params, m_buf, v_buf, step, num_steps)
print("step", step + 1, "/", num_steps, "| loss", t.node_data(loss_node))
# -------------------------------------------------------------------------
# 推論
# -------------------------------------------------------------------------
print("\n--- inference ---")
for si in range(20):
var infer_keys = List[List[List[Int]]]()
var infer_vals = List[List[List[Int]]]()
init_kv_cache(hp.n_layer, infer_keys, infer_vals)
var token_id = tok.bos
var result = String("")
for pos_id in range(hp.block_size):
var logits = gpt_forward(t, sd, hp, token_id, pos_id, infer_keys, infer_vals)
var probs = logits_with_temperature(t, logits^, 0.5)
token_id = sample_from_probs(probs, t)
if should_stop(token_id, tok.bos):
break
result += tok.uchars[token_id]
print("sample", si + 1, ":", result)
25.12.2. 解説
25.12.2.1. データ読み込みとシャッフル
var f = open("input.txt", "r")
var text = f.read()
f.close()
var docs = load_docs_from_text(text)
# Fisher-Yates シャッフル
for i in range(len(docs) - 1, 0, -1):
var j = Int(random_float64() * Float64(i + 1))
var tmp = docs[i]
docs[i] = docs[j]
docs[j] = tmp
Fisher-Yates シャッフルは末尾から先頭に向かって走査し、各要素をランダムな位置と入れ替えます。学習順序をランダム化することで、特定の文書の偏りを防ぎます。
25.12.2.2. 学習ループ
for step in range(num_steps):
var doc = docs[step % len(docs)] # docs を順番に使い回す
var keys = List[List[List[Int]]]()
var vals = List[List[List[Int]]]()
init_kv_cache(hp.n_layer, keys, vals) # KV キャッシュをリセット
var tokens = encode_doc(tok, doc)
var loss_node = loss_on_document(t, sd, hp, tokens, keys, vals)
backward(t, loss_node) # 勾配を計算
adam_update(t, params, m_buf, v_buf, step, num_steps) # 重みを更新
各ステップで KV キャッシュを初期化するのが重要です。KV キャッシュは1文書内の過去トークンを蓄積するもので、ステップをまたいで持ち越してはいけません。
25.12.2.3. 推論ループ
var token_id = tok.bos # BOS から生成スタート
for pos_id in range(hp.block_size):
var logits = gpt_forward(...)
var probs = logits_with_temperature(t, logits^, 0.5)
token_id = sample_from_probs(probs, t)
if should_stop(token_id, tok.bos): # BOS が出たら終了
break
result += tok.uchars[token_id]
BOS トークンを起点に1文字ずつ生成し、再び BOS が出たら(= 文の末尾を予測したら)停止します。block_size は生成の上限長になります。
25.13. Python 版との違いと実装上の工夫
25.13.1. なぜ Value 型ではなく Tape 型なのか
Python 版の Value はクラスのインスタンスで、参照によって計算グラフを形成します。
# Python: オブジェクト参照でグラフを作る
class Value:
def __init__(self, data, children=(), local_grads=()):
self._children = children # 別の Value オブジェクトへの参照
Mojo でこれを直接再現しようとすると問題が起きます。
struct Value:
var _children: List[Value] # ❌ Value が Value を含む → 無限サイズ
Mojo の struct は固定サイズでなければならないため、自己参照型は定義できません。また、所有権ルールにより List[Value] 内の要素を mut 参照で変更することも困難です。
解決策が テープ(Tape)パターンです。
struct Tape:
var data: List[Float64] # 全ノードの値
var grad: List[Float64] # 全ノードの勾配
var children: List[List[Int]] # 各ノードの子インデックス
var local_grads: List[List[Float64]]
ノード同士はインデックス(Int = NodeId)で参照します。Tape は複数の配列の束(SoA: Structure of Arrays)として表現されているので、サイズが固定でなくとも問題ありません。Python で言えば「グラフをオブジェクト参照で持つ」代わりに「グラフをインデックステーブルで持つ」イメージです。
25.13.2. inout/owned の廃止への対応
Mojo 0.26 では inout・owned キーワードが完全に削除されました。
旧構文 |
新構文 |
用途 |
|---|---|---|
|
|
コンストラクタ |
|
|
変更ありメソッド |
|
|
変更あり引数 |
|
|
所有権の転送 |
owned の代替として、呼び出し側で x^ を使いムーブ渡しします。
return Tokenizer(chars^, bos) # chars の所有権をコンストラクタに渡す
25.13.3. List[T] の所有権
List[T] はコピー不可能(ImplicitlyCopyable でない)です。別の変数に代入すると所有権が移動します。
var row = mat[0] # ❌ mat から行をコピーしようとしてエラー
var row = mat[0][j] # ✅ 要素(Int)はコピー可能
ネストしたリスト操作では要素インデックスで個別アクセスするのが基本方針です。children のような List[List[Int]] を取り出すときは .copy() が必要です。
var ch = tape.children[v].copy() # .copy() で明示的にコピー
25.13.4. 転送演算子 ^ と変数の再代入
x = rmsnorm(t, x^) # x を rmsnorm にムーブし、結果を x に代入
x^ は「x の所有権をここで放棄する」という宣言です。これ以降 x は未初期化になりますが、右辺の戻り値が即座に x に代入されるため問題ありません。
ただし同じスコープで x を複数の関数に渡す場合はムーブできないため、rmsnorm の結果を新しい変数名で受けています。
var x_ln = rmsnorm(t, x^) # x はムーブ後に無効化
# x_res(別途保存した残差)を使う
25.13.5. 初期化方法の違い
項目 |
Python 版 |
Mojo 版 |
|---|---|---|
重みの初期化 |
|
|
シード |
|
|
docs シャッフル |
|
Fisher-Yates + |
input.txt の取得 |
自動ダウンロード |
手動で配置(要事前準備) |
seed(42) を main.mojo の冒頭で呼ぶことで、重みの初期化・シャッフル・推論サンプリングすべてに同じシードが適用され、Python 版と同様に再現性が確保されます。
25.14. まとめ
B1〜B7 は
src/part3/microgpt_mojo/b0*.mojoに対応し、b*_test.mojoでブロック単位に検証できますTape パターンは Mojo の所有権制約のもとで計算グラフを安全に扱うための鍵です
Python の参照ベースの設計を、Mojo ではインデックスベースの SoA に置き換えることで、型安全性を保ちながら同等の自動微分を実現しています
inout/ownedの廃止、List[T]の所有権制約、^転送演算子など、Mojo 固有のルールに沿った書き方が全体を通して現れています
25.15. 次に読む章
26 章(MAX を導入する意味)へ進みます。